hive保序concat
品类里面取TOP2并按score分值连接成字符串
- row_number() 首先要排序。
- where rank < N 其次要进行过滤。
以上两步缺一不可
1 | select |
品类里面取TOP2并按score分值连接成字符串
1 | select |
冷启动( cold start )在推荐系统中表示该系统积累数据量过少,无法给新用户作个性化推荐的问题,这是产品推荐的一大难题。每个有推荐功能的产品都会遇到冷启动的问题。一方面,当新商品时上架 会遇到冷启动的问题,没有收集到任何一个用户对其浏览、点击或者购买的行为,也无从判断如何将商品进行推荐;另一方面,新用户到来的时候,如果没有他在应用上的行为数据,也无法预测其兴趣,如果给用户的推荐千篇律,没有亮点,会使用户在一开始就对产品失去兴趣,从而放弃使用。所以在冷启动的时候要同时考虑用户的冷启动和物品的冷启动。
用户冷启动主要解决如何给新用户作个性化推荐的问题。
英雄联盟,二次元,绝地求生等标签,然后冷启动会立即选择这几个品类的热门数据进行补充。物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。
推荐系统冷启动,可以通过人工标注的比较好的热门数据,作为兜底推荐。在推荐数据为空的情况下,通过兜底推荐也能保证用户和物品被推荐出去。
基于标签的相似视频推荐基本不存在冷启动问题,因为任何新注入的视频都是包含标签的,并且我们是近实时为新节目计算相似视频,在极短的时间内就会为新节目计算出相似推荐。本节我们来说说实时个性化推荐冷启动问题。
因为是基于内容的推荐,冷启动问题没有那么严重,只要用户看过一个视频,这个视频的标签就是用户的兴趣标签,我们可以为用户推荐具备该标签的节目。但是,如果用户一个节目都没看,那要怎么为用户做推荐呢?
我们可以采用如下3大策略:
利用大量的数据样本,使得计算机通过不断的学习获得一个模型,用来对新的未知数据做预测。
机器学习分为监督学习,非监督学习和强化学习。
监督学习:同时将数据样本和标签输入给模型,模型学习到数据和标签的映射关系,从而对新数据进行预测。监督学习又分为分类问题和回归问题。
非监督学习:只有数据,没有标签,模型通过总结规律,从数据中挖掘出信息。
因为数值缩放不影响分裂点位置,对树模型的结构不造成影响。树模型是不能进行梯度下降的,因为构建树模型(回归树)寻找最优点时是通过寻找最优分裂点完成的,因此树模型是阶跃的,阶跃点是不可导的,并且求导没意义,也就不需要归一化。归一化对模型没有影响。
问题来了,为何非树形结构比如 Adaboost、SVM、LR、Knn、KMeans 之类则需要归一化呢?
对于线性模型,特征值差别很大时,比如说 LR ,我有两个特征,一个是 (0,1) 的,一个是 (0,10000) 的,运用梯度下降的时候,损失等高线是椭圆形,需要进行多次迭代才能到达最优点。
但是如果进行了归一化,那么等高线就是圆形的,促使 SGD 往原点迭代,从而导致需要的迭代次数较少。在实际应用中,通过梯度下降法求解的模型一般都是需要归一化的,比如线性回归、logistic回归、KNN、SVM、神经网络等模型。
标准差归一化
非线性归一化
幂律分布可用log(v, 2) / log(max, 2)
指数归一化
反正切函数 arctan
对于某件商品或广告X,其是否被点击是一个伯努利分布(Bernoulli)
求解$\alpha, \beta$
然而,Beta分布除了两个显性的重要参数α和β外,还有两个相对隐形但同样重要的参数,平均值和中位数,通过平均值和中位数可以唯一确定α和β的值,它们的数学关系如下:
平滑,曝光次数n,点击率p
它只适用于样本较多的情况(np > 5 且 n(1 − p) > 5),对于小样本,它的准确性很差。
独热编码
独热编码通常用于处理类别间不具有大小关系的特征,每个特征取值对应一维特征,能够处理缺失值,在一定程度上也起到了扩充特征的作用。但是当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用 PCA 等方法进行降维。
散列编码
对于有些取值特别多的类别特征,使用独热编码得到的特征矩阵非常稀疏,再加上如果还有笛卡尔积等构造的组合特征,会使得特征维度爆炸式增长。使用2-3倍取模。
打分排名编码
伯努利分布,又名两点分布或者0-1分布,是一個离散型概率分布。有两种可能的结果:
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
场景:射手进入训练或比赛场地后,首先观察好自己所射的靶位,以及场地上的情况和周围的环境,并针对光线、湿度、风向和风力等客观因素可能带来的影响作好思想准备。
从场景分析,可以知道,主要是射手的经验,以及环境的相互作用,才能评估最后是否射中靶心。
一直苦于 Windows 下没有如 Mac 一般好用的 iterm2, 没有如 linux 一样好用的环境。经常折腾于双系统和 VM 之间。今天给大家推荐一款个人总结的 windows 下最完美的开发环境。子系统和 windows 公用目录且权限统一,操作及其方便。废话不多说先上图!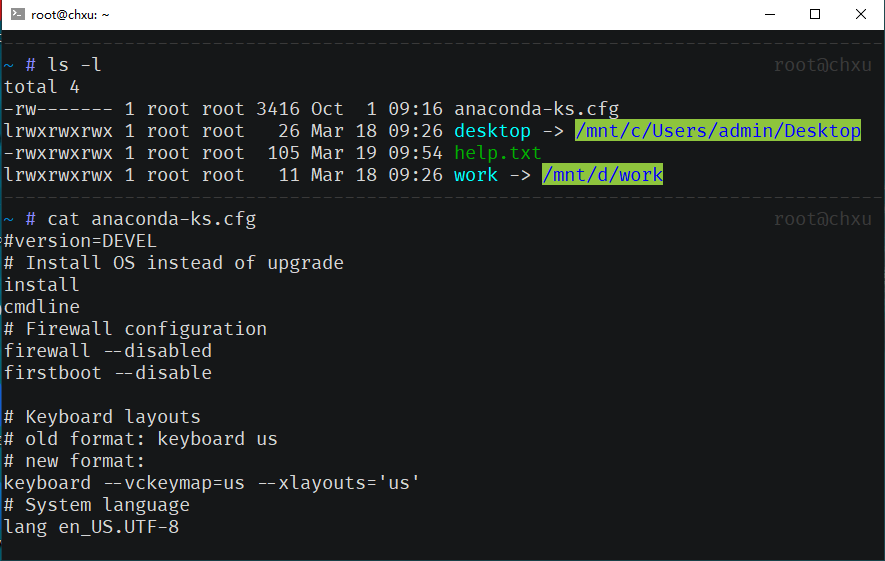
让我们开始吧~
关于如何打开子系统我不介绍了。可以参考链接。
在 Linux 下,大家喜欢用 apt-get , yum 来安装应用程序,如今在 windows 下,大家可以使用 Chocolatey 来快速下载搭建一个开发环境。
用管理员身份打开 powershell , 然后运行下面一句
1 | Set-ExecutionPolicy AllSigned; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1')) |
如有问题,参考链接1
安装 lxrunoffline
1 | choco install lxrunoffline |
1 | # 查看系统中已安装的 WSL |
[1]. Windows 系统的包管理器
问题: Windows 下文件夹占用解决办法
解决办法:
win10 子系统 wsl 安装的 ubuntu,sudo apt-get install python3 时候出现。1
2~ # sudo apt-get install python3
E: Could not read response to hello message from hook [ ! -f /usr/bin/snap ] || /usr/bin/snap advise-snap --from-apt 2>/dev/null || true: Success
解决方法:1
~ # sudo rm -rf /etc/apt/apt.conf.d/20snapd.conf